Collision Avoidance RL Agent
2025A collision avoidance RL agent that uses a DQN algorithm to navigate a 2D environment.
Training Progress Demo
Watch the agent's learning progress from no training to fully trained
Randomly moving
Learning to navigate
Optimal behavior
Project Overview
Observation Space
Observation Space Approaches
One of the challenges of this project was the observation space. I thought of two possible observation spaces: 1. Develop a grid-like sample of the environment around the agent. Each grid component would get an encoded value indicating whether the location was a wall, goal, or obstacle. The grid component would also receive horizontal and vertical velocity information. 2. Create rays around the agent that indicate the distance to the nearest wall or obstacle. Also include normal and tangential velocity information of whatever the ray is hitting. Option 1 provides more information to the agent and doesn't limit its vision to what's immediately around it, since the agent's "vision" wouldn't be blocked by the obstacles it hit. Option 2 included less information
Grid
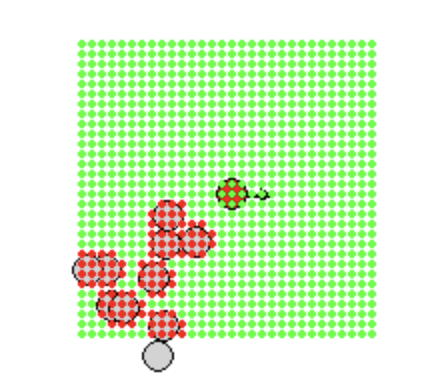
Grid sampling with encoded values for walls, goals, and obstacles
Rays
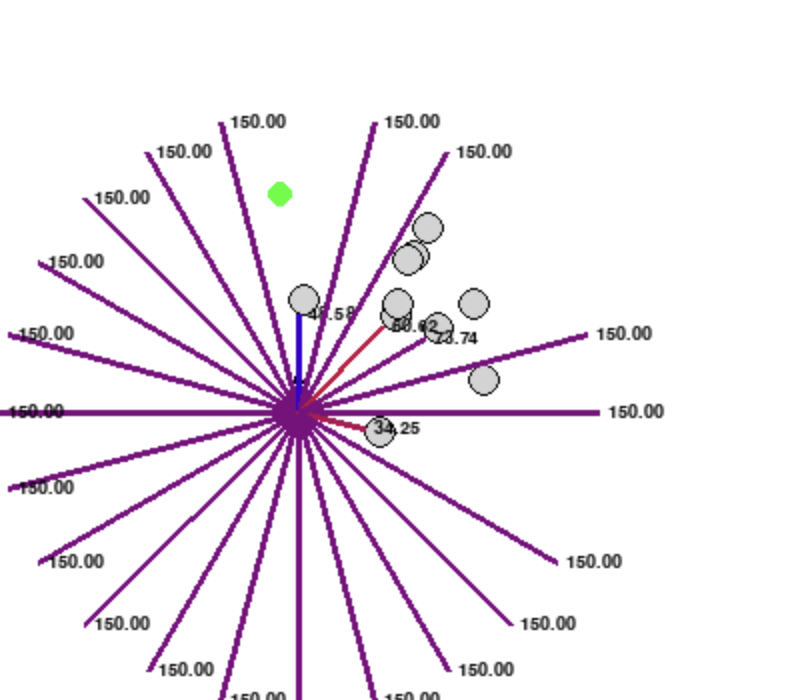
Ray casting with distance and velocity information
Reward Shaping
I had to take careful consideration when shaping the rewards. Naturally, I wanted to give the agent a large reward when the goal was reached and a large penalty when the agent hit an obstacle. I found I had to carefully balance the reward and penalty to encourage the agent to move quickly towards the goal, but also take the time to avoid obstacles if needed. At a reward of 1000 and collision penalty of -150, I found the agent was not conservative enough and was willing to risk a collision to reach the goal. In a real life scenario like a driverless car, that's not acceptable. I increased the penalty to -500 which yielded an agent that was less willing to risk collision.
With the above settings, the agent only receives a reward at the end of the episode. This is tricky for RL algorithms, since for most of the episode the agent receives 0 feedback. It has little guidance about what's good or bad until it reaches the end. To address this, I implemented a very small reward for moving towards the goal and small penalty for moving away. This gives the agent more signal to learn from. If it's closer to the goal that's generally better!
Lastly, I included a small time penalty to encourage the agent to move quickly.
On-Policy vs Off-Policy
I tried two reinforcement learning algorithms: DQN and PPO. A core difference is DQN is off-policy while PPO is on-policy. Off-policy models can learn from any experiences collected at any point in time. On-policy models only learn from experiences that are collected with the current policy.
Imagine I was learning football and had years of training tapes of my plays. Should I study and learn from only my most recent games? Or should I continue to learn from all of my games, good or bad, over the years? PPO might study from only the most recent, while DQN would study from all of them.
This makes PPO very sample inefficient, since it throws away a lot of the old data it collected. The benefit of PPO is that the learning is generally more stable since it's learning from its most recent experiences, which is most likely the best solution.
I found the PPO model took significantly longer to train than the DQN model, but exhibited stable growth and didn't require fine tuning. The DQN model requires exploration rate and learning rate schedules to fine tune what it learns and avoid getting stuck in local optima.
Results & Impact
- Success rate of 66% in the final model
- Reduced average timesteps to completion from 250 to 80